Tianwei Ni 倪天炜
I am a final-year PhD student at Mila - Quebec AI Institute and Université de Montréal,
advised by Pierre-Luc Bacon. In the previous years, I worked closely with
Benjamin Eysenbach at Princeton University and Aditya Mahajan at McGill University.
I also worked at Amazon as an applied scientist intern, supervised by Rasool Fakoor and Allen Nie.
I research reinforcement learning (RL),
with a focus on uncertainty (partial observability and epistemic uncertainty)
and generalization through representation and adaptation.
I study a range of RL training paradigms and the interplay between model-free and model-based approaches, and I believe that integrating them is key to building strong AI systems:
News
- Dec 2025: One paper on offline model-based RL got accepted at NeurIPS 2025 workshop.
- Oct 2025: One paper on LLM math reasoning got accepted at TMLR.
- May 2025: One paper on representation learning in RL got accepted at RLC. See you in UAlberta, Edmonton.
- Nov 2024: I am honored to receive the RBC Borealis AI fellowship (10 PhD students in Canada every year).
- Sept 2024 - Feb 2025: I started my applied scientist internship at AWS in Santa Clara in the generalist agent team.
- Jan 2024: One paper on representation learning in RL got accepted at ICLR as a poster. See you in Vienna!
- Sept 2023: One paper on memory-based RL got accepted at NeurIPS as an oral. See you in New Orleans!
|
|
Recent Work
Please see the full publication list in Google Scholar.
Notation: * indicates equal contribution.
|
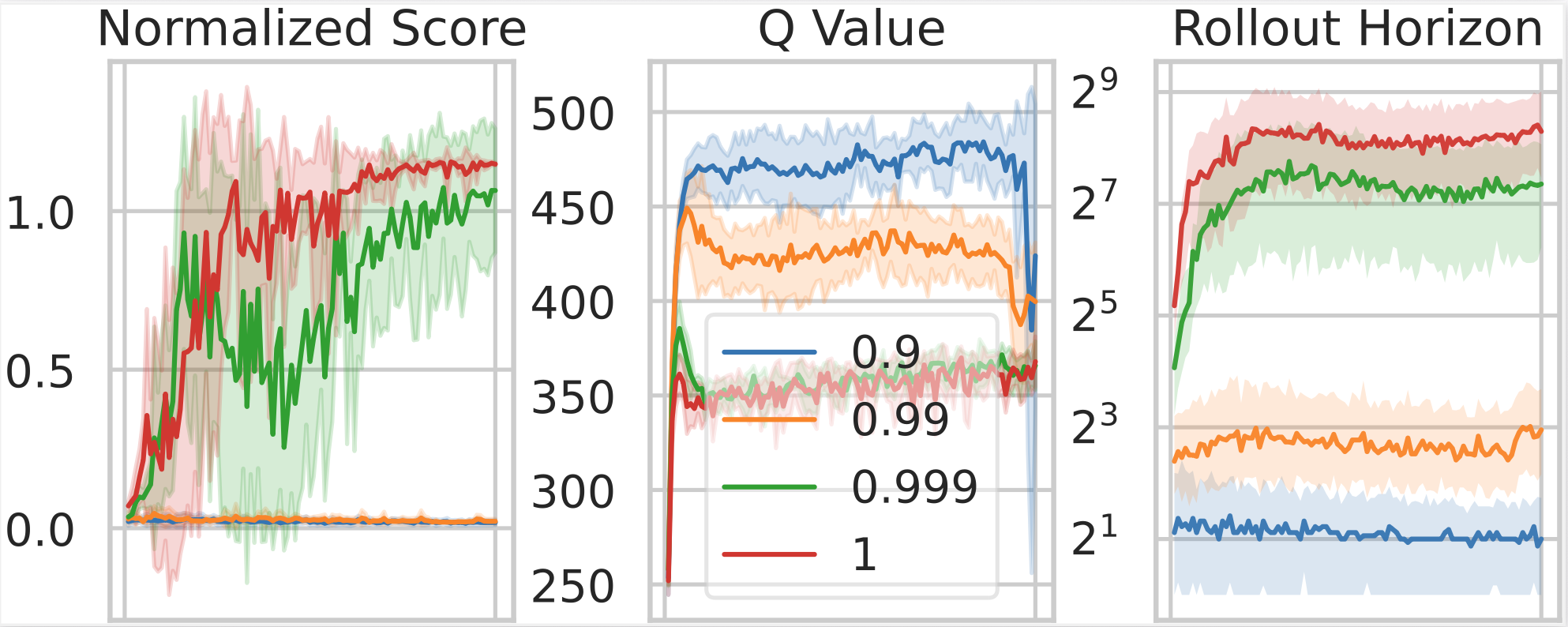
Long-Horizon Model-Based Offline Reinforcement Learning Without Conservatism
Tianwei Ni, Esther Derman, Vineet Jain, Vincent Taboga, Siamak Ravanbakhsh, Pierre-Luc Bacon
NeurIPS Workshop on Aligning Reinforcement Learning Experimentalists and Theorists, 2025
arXiv /
Offline RL methods rely heavily on conservatism, but conservatism hinders generalization. To pursue Bayes-adaptive generalization, this work discovers key design choices to make the Bayesian principle practical in offline RL for the first time.
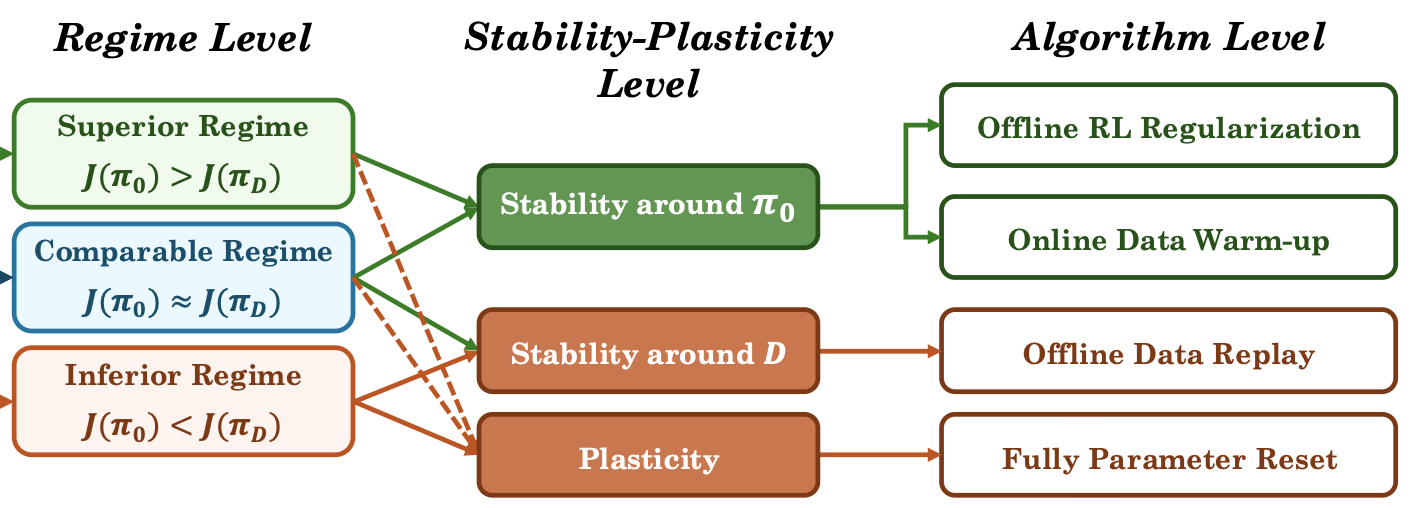
The Three Regimes of Offline-to-Online Reinforcement Learning
Lu Li, Tianwei Ni, Yihao Sun, Pierre-Luc Bacon
Preprint, 2025
arXiv
We introduce a stability-plasticity principle for online RL fine-tuning: we should not only preserve prior knowledge from the pretrained policy or offline dataset, whichever is better, but also retain sufficient plasticity to acquire new knowledge.
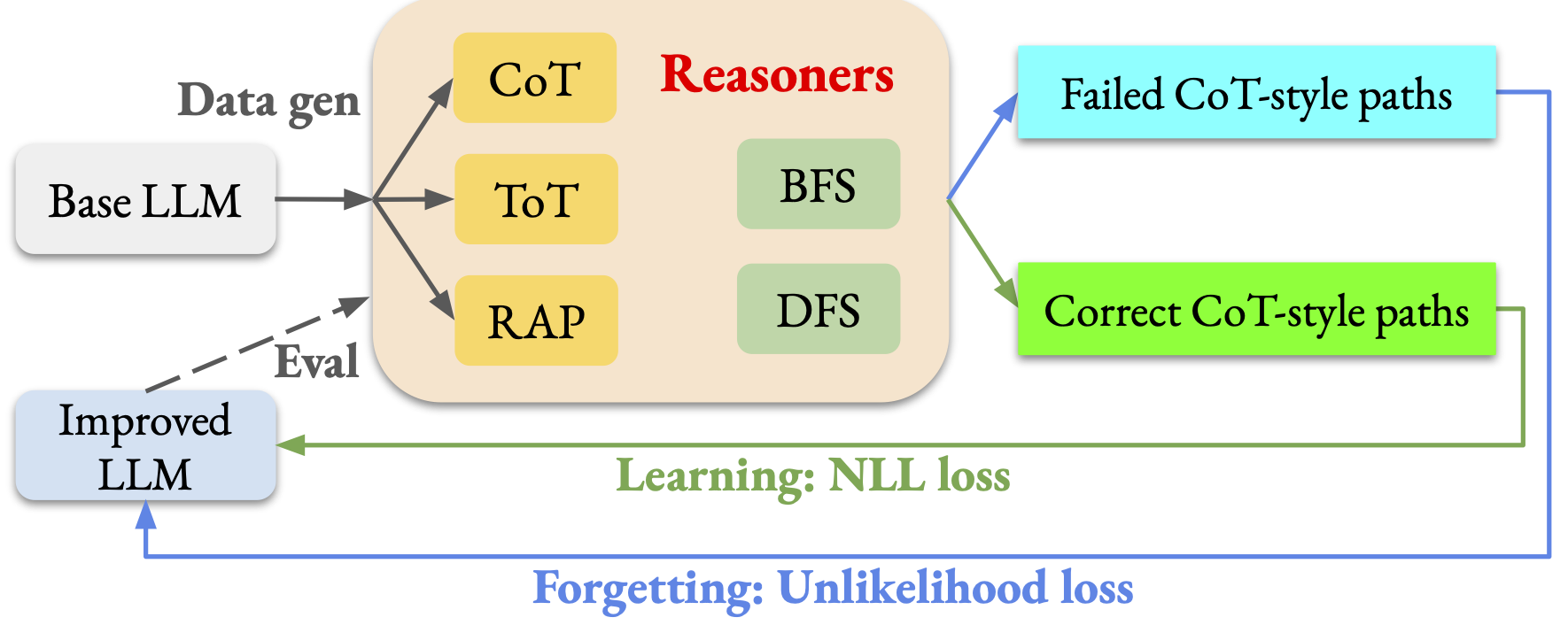
Offline Learning and Forgetting for Reasoning with Large Language Models
Tianwei Ni, Allen Nie, Sapana Chaudhary, Yao Liu, Huzefa Rangwala, Rasool Fakoor
Transactions on Machine Learning Research (TMLR), 2025
arXiv / Thread /
Inference-time search improves reasoning in LLMs but is expensive at deployment.
We offline fine-tune LLMs to follow correct reasoning paths and forget wrong ones collected from various reasoning algorithms,
while enabling fast inference.
Understanding Behavioral Metric Learning: A Large-Scale Study on Distracting Reinforcement Learning Environments
Ziyan Luo, Tianwei Ni, Pierre-Luc Bacon, Doina Precup, Xujie Si
Reinforcement Learning Conference (RLC), 2025
arXiv / Blog / Thread /
Distracting observations in the real world can be addressed by metric learning in RL.
Our extensive study highlights the often-overlooked roles of layer normalization and self-prediction in improving these methods.
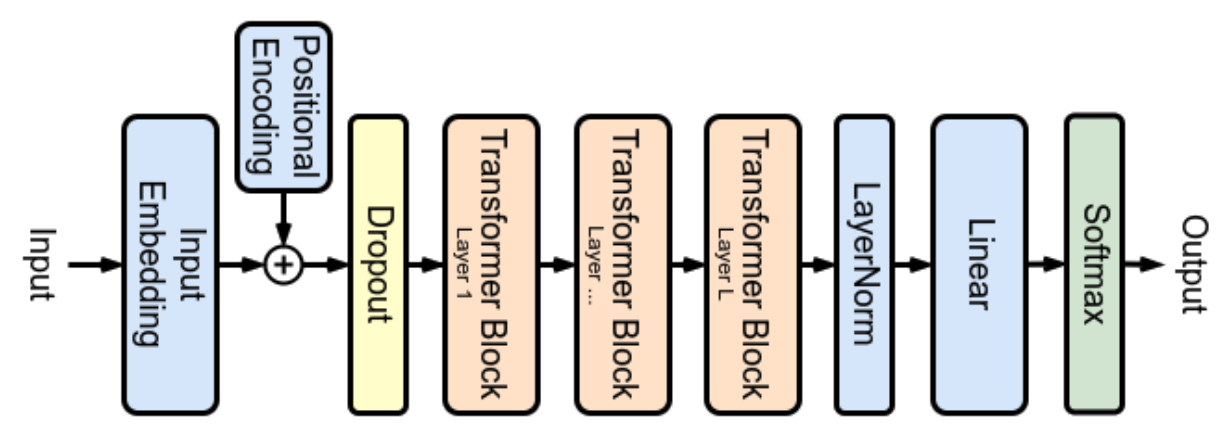
Do Transformer World Models Give Better Policy Gradients?
Michel Ma*, Tianwei Ni, Clement Gehring, Pierluca D'Oro*, Pierre-Luc Bacon
International Conference on Machine Learning (ICML), 2024
and ICLR Workshop on Generative Models for Decision Making (oral), 2024
arXiv / Thread
How to design world models for long-horizon planning w/o policy gradient explosion?
Use f(s[0], a[0:t]) w/ Transformer, instead of recursively calling f(s[t], a[t]).
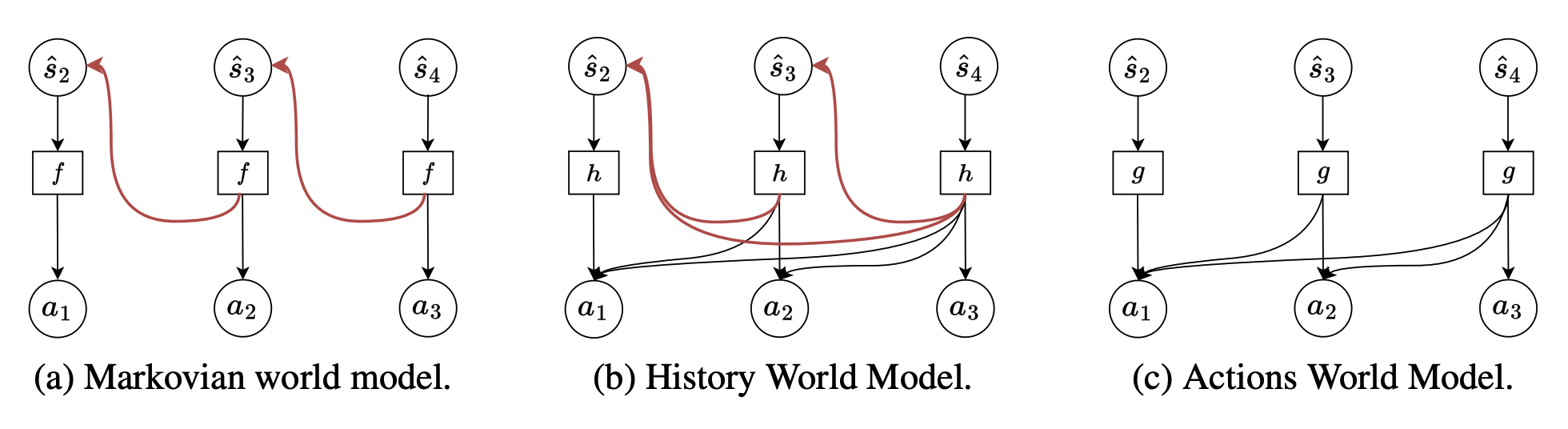
Bridging State and History Representations: Understanding Self-Predictive RL
Tianwei Ni, Benjamin Eysenbach, Erfan Seyedsalehi, Michel Ma, Clement Gehring, Aditya Mahajan, Pierre-Luc Bacon
International Conference on Learning Representations (ICLR), 2024
and NeurIPS Workshop on Self-Supervised Learning: Theory and Practice (oral), 2023
arXiv / OpenReview / Poster / 1-hour Talk / Thread /
Provide a unified view on state and history representations in MDPs and POMDPs, and further investigate
the challenge, solution, and benefit of learning self-predictive representations in standard MDPs, distracting MDPs, and sparse-reward POMDPs.
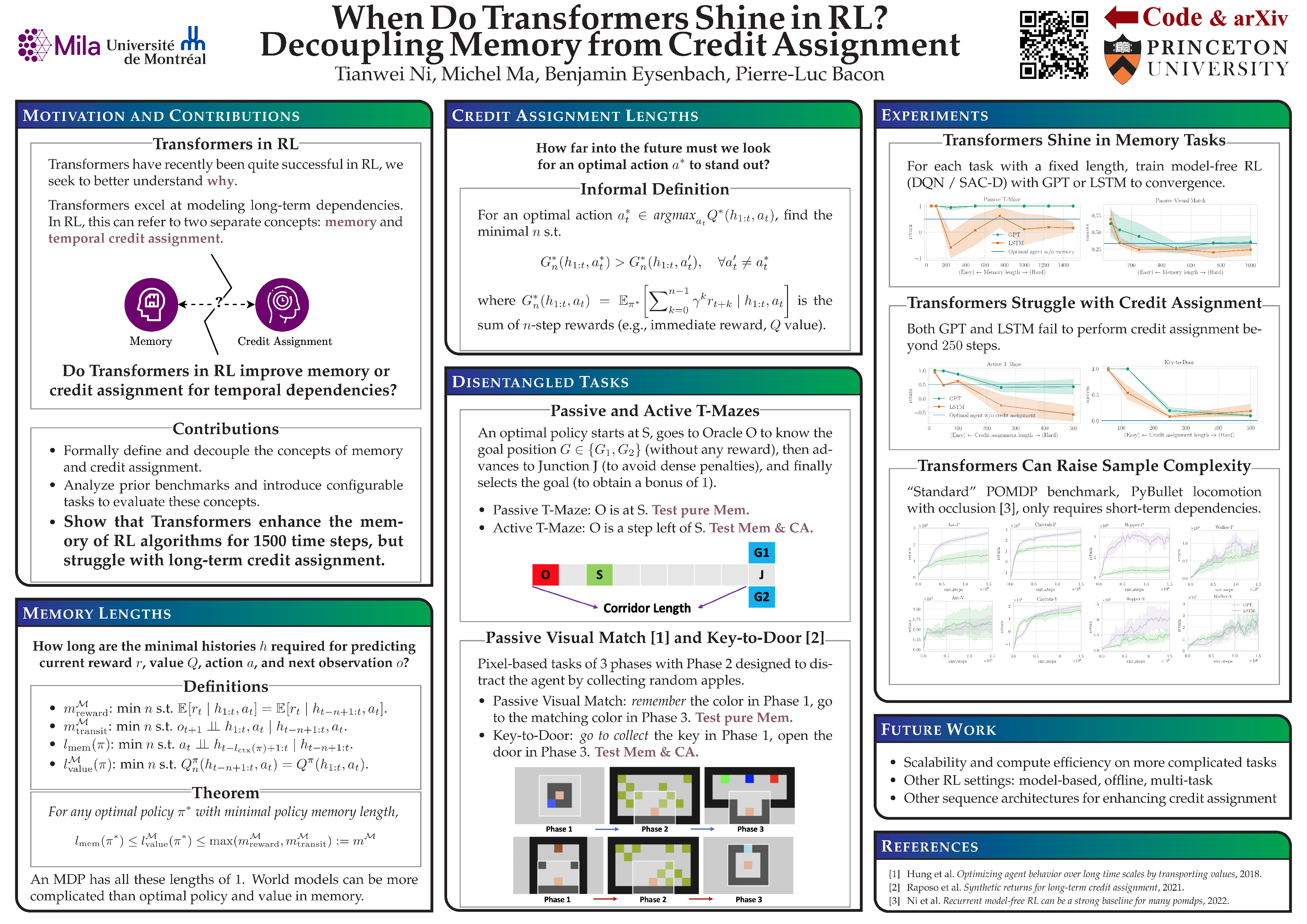
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
Tianwei Ni, Michel Ma, Benjamin Eysenbach, Pierre-Luc Bacon
Conference on Neural Information Processing Systems (NeurIPS), 2023 (oral)
and NeurIPS Workshop on Foundation Models for Decision Making, 2023
arXiv / OpenReview / Poster /
11-min Talk / Mila Blog /
Investigate the architectural aspect of history representations in RL on temporal dependencies -- memory and credit assignment, with rigorous quantification.
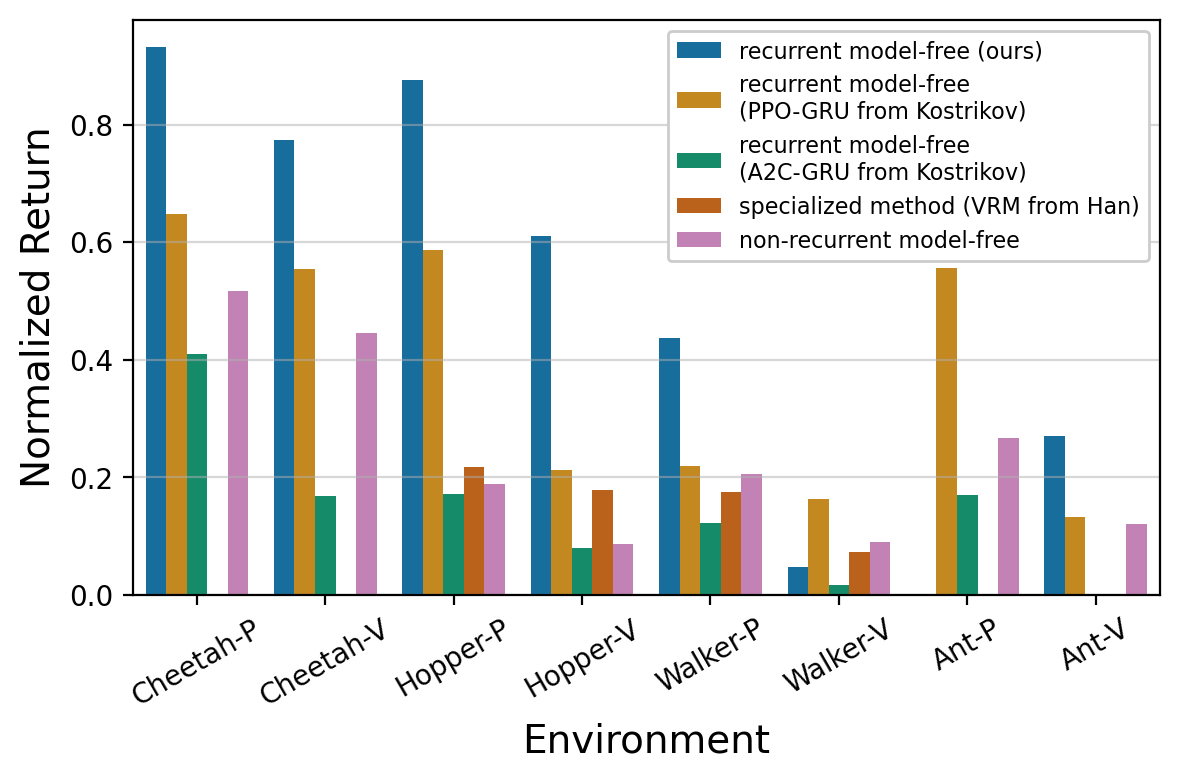
Recurrent Model-Free RL Can Be a Strong Baseline for Many POMDPs
Tianwei Ni, Benjamin Eysenbach, Ruslan Salakhutdinov
International Conference on Machine Learning (ICML), 2022
project page / arXiv
/ CMU ML Blog /
Find and implement simple but often strong baselines for POMDPs,
including meta-RL, robust RL, generalization in RL, and temporal credit assignment.
f-IRL: Inverse Reinforcement Learning via State Marginal Matching
Tianwei Ni*, Harshit Sikchi*, Yufei Wang*, Tejus Gupta*,
Lisa Lee°, Benjamin Eysenbach°
Conference on Robot Learning (CoRL), 2020
project page
/
arXiv
/
Learn reward functions from state-only demonstrations with f-divergence matching.
Before embarking on my PhD journey, I was a research intern on embodied AI mentored by Jordi Salvador and Luca Weihs at Allen Institute for AI (AI2).
I earned my Master's degree in Machine Learning at Carnegie Mellon University, where I
studied deep RL guided by Ben Eysenbach and Russ Salakhutdinov, and explored human-agent collaboration advised by Katia Sycara.
My research journey started with computer vision for medical images supervised by Alan Yuille at Johns Hopkins University.
I earned my Bachelor's degree in Computer Science at Peking University.
Fun fact: I have experienced university education in three languages - Chinese, English, and French.
|
Website template is credit to Jon Barron's source code.
|
|


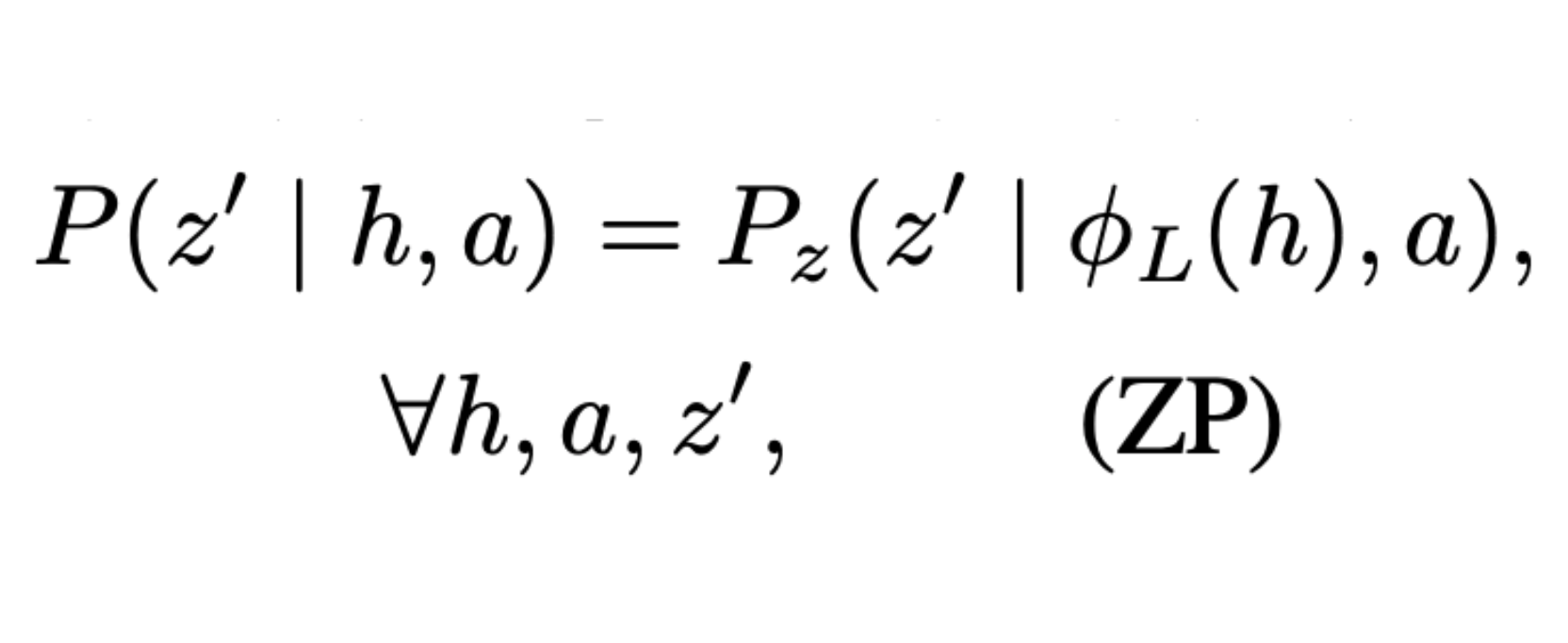
{kind=link}